Prototype(객체)이란, 새로 생성된 인스턴스(객체)의 부모의 역할을 하는 객체를 말한다. 여기서 부모의 역할이란, 새로 생성된 인스턴스(객체)가 부모 객체의 프로퍼티 또는 메소드를 상속받아 사용할 수 있다는 뜻이다. Prototype 객체는 생성자 함수에 의해 생성된 각각의 객체에 공유 프로퍼티를 제공하기 위해 사용한다.
Java, C++과 같은 클래스 기반 객체지향 프로그래밍 언어와 달리 자바스크립트는 프로토타입 기반 객체지향 프로그래밍 언어이다.
클래스 기반 객체지향 프로그래밍 언어는 객체 생성 이전에 클래스를 정의하고 이를 통해 객체(인스턴스)를 생성한다. 하지만 프로토타입 기반 객체지향 프로그래밍 언어는 클래스 없이(Class-less)도 객체 리터럴 방식 또는 생성자 함수를 이용해서 객체를 생성할 수 있다. (ECMAScript 6에서 클래스가 추가되었다)
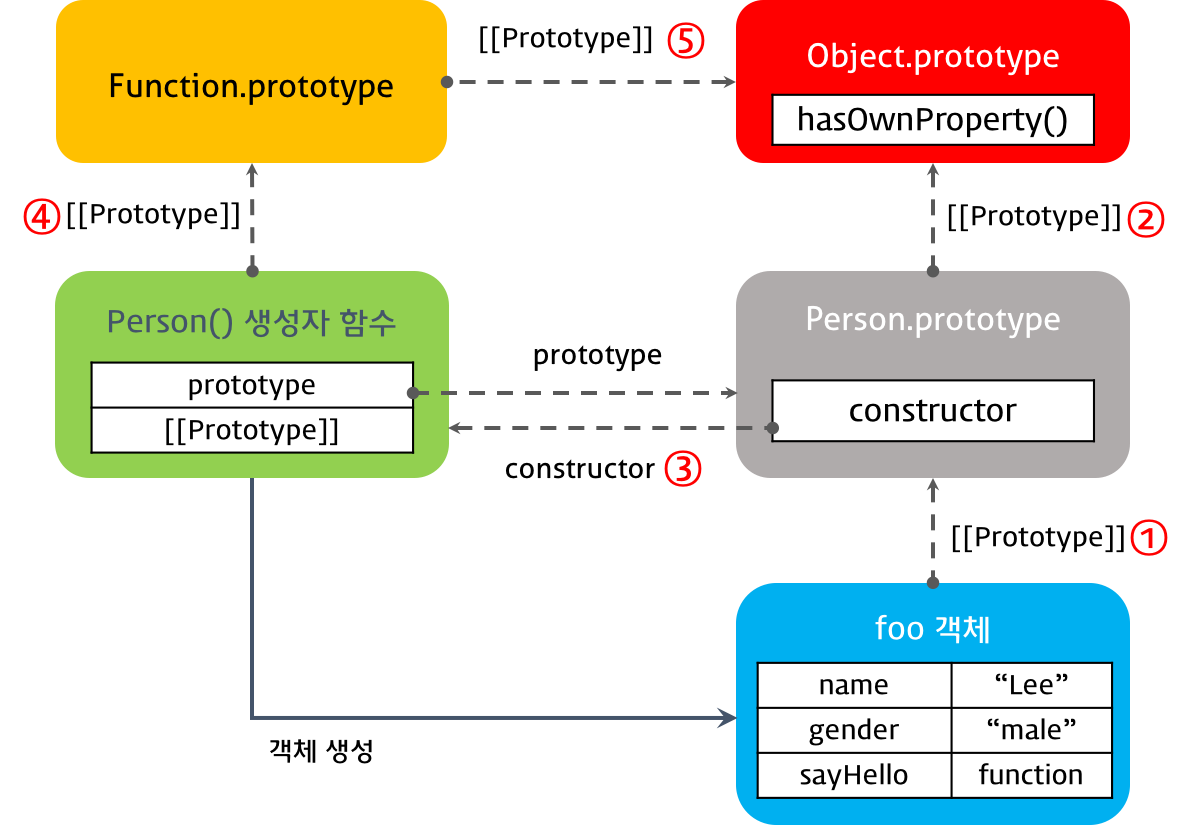
어떤 생성자 함수(Person 생성자 함수)에 의해 인스턴스(foo 객체)가 생성되면, 그 인스턴스의 부모 역할을 하는 프로토타입 객체(Person.prototype)가 결정된다. 위 그림에서, 생성된 인스턴스는 name, gender 프로퍼티와, sayHello 메소드를 가지고 있다.
ECMAScript spec에서는 자바스크립트의 모든 객체는 자신의 프로토타입을 가리키는 [[Prototype]]이라는 숨겨진 프로퍼티를 가진다 라고 되어있다. 크롬, 파이어폭스 등에서는 숨겨진 [[Prototype]] 프로퍼티가 __proto__ 프로퍼티로 구현되어 있다. 즉, __proto__과 [[Prototype]]은 같은 개념이다.
foo 객체는 __proto__ 프로퍼티로 자신의 부모 객체(프로토타입 객체)인 Person.prototype을 가리키고 있다.
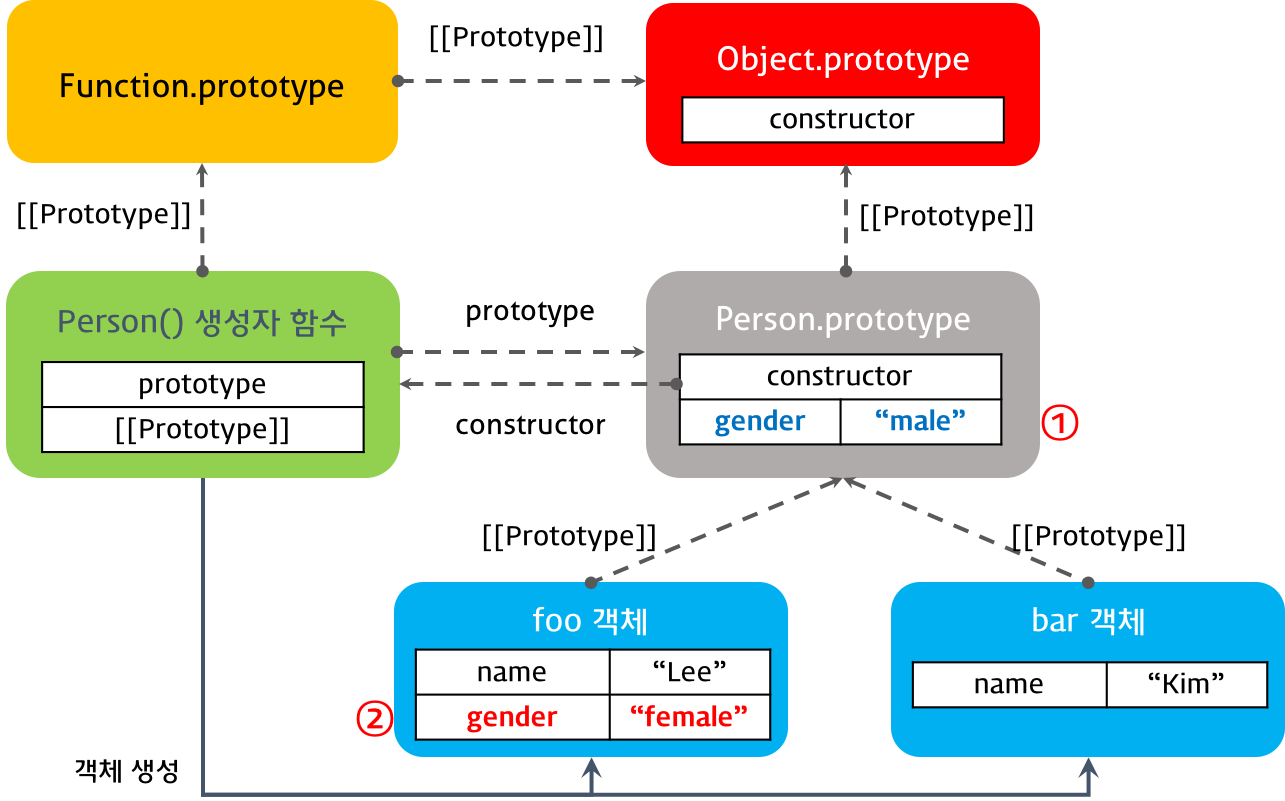
객체를 생성할 때 프로토타입은 결정된다. 결정된 프로토타입 객체는 다른 임의의 객체로 변경할 수 있다. 이것은 부모 객체인 프로토타입을 동적으로 변경할 수 있다는 것을 의미한다. 이러한 특징을 활용하여 객체의 상속을 구현할 수 있다.
constructor 프로퍼티
프로토타입 객체는 constructor 프로퍼티를 갖는다. 이 constructor 프로퍼티는 객체의 입장에서 자신을 생성한 객체를 가리킨다.
예를 들어 Person() 생성자 함수에 의해 생성된 객체를 foo라 하자. 이 foo 객체를 생성한 객체는 Person() 생성자 함수이다. 이때 foo 객체 입장에서 자신을 생성한 객체는 Person() 생성자 함수이며, foo 객체의 프로토타입 객체는 Person.prototype이다. 따라서 프로토타입 객체 Person.prototype의 constructor 프로퍼티는 Person() 생성자 함수를 가리킨다.
Prototype Chain
자바스크립트는 특정 객체의 프로퍼티나 메소드에 접근하려고 할 때 해당 객체에 접근하려는 프로퍼티 또는 메소드가 없다면 [[Prototype]] 프로퍼티가 가리키는 링크를 따라 자신의 부모 역할을 하는 프로토타입 객체의 프로퍼티나 메소드를 차례대로 검색한다. 이것을 프로토타입 체인이라 한다.
프로토타입 체인 동작 조건
객체의 프로퍼티를 참조하는 경우, 해당 객체에 프로퍼티가 없는 경우, 프로토타입 체인이 동작한다.
객체의 프로퍼티에 값을 할당하는 경우, 프로토타입 체인이 동작하지 않는다. 이는 객체에 해당 프로퍼티가 있는 경우, 값을 재할당하고 해당 프로퍼티가 없는 경우는 해당 객체에 프로퍼티를 동적으로 추가하기 때문이다.
클로저란, 외부함수와 내부함수가 있을 때, 외부함수에 의해 내부함수가 반환된 이후에도, 내부함수에서 외부함수에 있는 변수를 참조할 수 있는 것을 말한다.
조건 3가지
외부함수와 내부함수가 존재
내부함수가 외부함수에 있는 변수를 참조해야 한다.
외부함수가 내부함수를 return(라이프사이클과 관련) 해야한다.
내부함수가 외부함수보다 더 긴 라이프 사이클을 가지고 있을때, 외부함수에 있는 변수를 내부함수가 참조하는데, 그 변수의 값은 유지되어있다.
실행 컨텍스트의 관점에서 이해해보자.
기본적으로 실행 컨텍스트는 함수가 종료되면, 실행 컨텍스트 스택에서 제거된다. 그래서 외부함수에서 내부함수를 반환하고, 모두 실행이 되면, 외부함수의 실행 컨텍스트는 제거된다. 그럼에도 불구하고, 내부함수에서 외부함수의 실행 컨텍스트 내에 있는 활성 객체는 유효하기 때문에, 내부함수에서 외부함수의 변수를 참조할 수 있다. (이때, 이 변수를 자유변수라고 한다.) 이는 내부함수가 스코프 체인을 통해 참조하려는 변수를 먼저 내부함수에서 찾고(내부함수 안에 있는 스코프체인의 ‘0’이 가리키는 활성객체에 참조하려는 변수가 있는지 확인한다.), 없으면, 상위지역인 외부함수에서 찾는다.(내부함수 안에 있는 스코프체인의 ‘1’이 가리키는 활성객체, 즉 외부함수의 활성객체에 들어있는 변수를 말한다.) 이때 내부함수가 외부함수에 있는 변수의 복사본이 아니라, 실제 변수에 접근하는 것이다.
위 내용을 예제와 함께 요약하면 다음과 같다.
1 2 3 4 5 6 7 8
function outerFunc() { var x = 10; var innerFunc = function () { console.log(x); }; return innerFunc; }
var inner = outerFunc(); inner(); // 10
순서
외부함수(outerFunc)가 내부함수(innerFunc)를 반환하고, 외부함수는 종료된다.(이때, 외부함수의 실행 컨텍스트는 실행 컨텍스트 스택에서 제거된다.)
내부함수에서 변수 x를 참조하려 할 때, 먼저 내부함수(자기자신) 내에서 그 변수를 찾는다.(내부함수의 스코프체인의 ‘0’이 가리키는 활성객체내에 변수 x를 찾는다.)
내부함수내에 없으면, 그 내부함수를 포함하고 있는 외부함수 내에서 그 변수를 찾는다.(내부함수의 스코프체인의 ‘1’이 가리키는 활성객체내에 변수 x를 찾아 참조한다.)
실행 컨텍스트란, 실행 가능한 코드가 실행되기 위해 필요한 환경을 의미하는데, 이 환경은 코드가 실행되기 전에 설정이 된다. 이때, 실행 가능한 코드는 총 3개(전역코드/함수코드/Eval코드)가 있는데, 일반적으로 전역코드/함수코드를 말한다. 여기서 환경이 설정된다는 것은 실행에 필요한 여러가지 정보를 담는다는 뜻이다.
코드가 전역변수와 외부함수 그리고 그 안에 내부함수 있다고 해보자.
코드가 실행되기 전, 전역에 실행 컨텍스트가 생성이 되는데, 이것을 전역 실행 컨텍스트라고 한다. 전역 실행 컨텍스트가 생성이 되면, 실행 컨텍스트 스택(콜 스택)에 추가된다. 그리고, 외부함수가 호출이 되면, 외부함수가 실행되기 전에 외부함수에 대한 실행 컨텍스트가 생성이 되는데, 이것을 함수 실행 컨텍스트라고 한다. 이 외부함수 실행 컨텍스트 또한 실행 컨텍스트 스택에 그 전에 추가된 전역 실행 컨텍스트 위에 쌓이게 된다. 내부함수 또한 호출되면, 내부함수 실행되기 전에 내부함수 실행 컨텍스트가 생성되고, 실행 컨텍스트 스택에 있는 외부함수 실행 컨텍스트 위에 쌓이게 된다.
전체적인 과정에서 봤을때, 코드의 종류(전역코드/함수코드)에 따라 실행 컨텍스트가 생성되고, 실행 컨텍스트 스택에 쌓이는 구조이다.
실행 컨텍스트가 생성되고 코드가 실행되기 전에, 실행 컨텍스트는 3가지 프로퍼티를 가지게 된다.
Scope Chain
VO(변수객체)
thisvalue
실행 컨텍스트가 생성이 되면, 먼저 Scope Chain이라는 전역 객체 또는 활성 객체를 가리키는 리스트가 생성되고 초기화 된다. 리스트는 배열처럼 ‘0’: {}, ‘1’: {}, 이런 방식으로 생성되는데, ‘0’은 자기자신(위치)를 가리키고, 1은 자기 위치의 상위 지역을 가리킨다. 예를 들어, 외부함수의 Scope Chain의 ‘0’은 자기 자신인 외부함수를 가리키고, ‘1’은 외부함수의 상위지역인 전역코드를 가리킨다. 좀 더 구체적으로 말하면, ‘0’은 자기자신(외부함수)가 가지고 있는 활성객체(A0)를 가리키고, ‘1’은 상위지역인 전역코드가 가지고 있는 전역객체(GO)를 가리킨다. 그리고, 변수 객체(VO)가 생성되어, 각 코드(전역코드/함수코드)가 가지고 있는 객체를 담는다. 전역코드의 경우, 전역함수와 전역변수를 가지고 있고, 함수코드의 경우, arguments, 내부함수, 지역변수 등을 가지고 있다.
this의 값은 문맥에 따라 결정이 되는데, 예외사항이 아니면 전역객체를 가리킨다.
위 내용을 요약하면 다음과 같다.
순서
브라우저안에 기본적으로 전역객체(window)가 존재
(브라우저에서) 코드가 실행되기전, 전역 실행 컨텍스트가 생성
전역 실행 컨텍스트가 생성되면서, Scope Chain의 리스트 생성 및 초기화(이때, Scope Chain의 리스트 ‘0’은 전역객체를 가리킨다)
변수객체의 생성후, 변수객체에 전역변수 및 전역함수를 추가
전역함수를 추가할 때, 전역 함수 객체는 [[Scopes]] 프로퍼티를 가짐(이 프로퍼티는 함수 객체만이 소유하는 내부 프로퍼티로, 함수 객체가 실행되는 환경을 가리킨다.)
this 값이 결정되기 이전에 this는 전역 객체를 가리키다가, 함수 호출 패턴에 의해 this에 할당되는 값이 결정됨
전역코드가 실행(예를 들어, 전역변수에 값이 할당되고, 전역함수가 호출됨)
외부함수가 호출되면, 외부함수에 대한 실행 컨텍스트 생성
외부함수도 전역 실행 컨텍스트와 같은 방식으로 진행
이때, 외부함수의 변수객체에는 arguments, 내부함수, 지역변수 등이 포함됨
외부함수 실행
내부함수도 위와 동일
위에서 생성된 각 실행 컨텍스트가 순서대로 실행 컨텍스트 스택에 하나씩 쌓이고, 함수 실행이 끝나면, 해당 함수의 실행 컨텍스트가 제거된다. 전역 실행 컨텍스트는 애플리케이션이 종료될 때까지 유지된다.!!
ES5까지는 var를 사용했으나, var가 가지고 있는 단점들을 보완하기 위해 ES6에서는 let 과 const를 사용할 수 있다.
var는 중복선언이 가능했으나, let과 const는 불가능하다.
var a = 3; 이렇게 선언을 했어도, 다시 var a = 10; 이런식으로 중복 선언이 가능하다. 이는 의도치 않게 변수값을 변경하는 문제가 발생하게 된다. 하지만, let과 const로 선언을 할 경우, 중복선언을 하려고 하면, 에러가 발생하게 된다. 이렇게, let과 const를 사용하게 되면 중복선언을 미리 막을 수 있다.
유효범위가 다르다.
var를 이용한 변수 선언은 유효범위가 함수레벨이다. 즉, 함수내에서는 지역변수이고, 함수 밖에서는 전역변수이다. let과 const를 이용한 변수 선언은 유효범위가 블록레벨이다. 즉, 블록내에서는 지역변수이고, 블록 밖에서는 전역변수이다.
let 과 const 차이점
const는 상수(변하지 않는 값)를 위해 사용한다.(그렇다고 꼭 상수만을 위한 것은 아니다.)
let은 재할당이 가능하고, const는 불가능하다.
const는 반드시 선언과 동시에 할당이 이루어져야 한다. 그렇지 않으면, 문법에러가 발생한다.
const 변수의 객체인 경우도 재할당이 불가능하다. 즉, 객체에 대한 참조를 변경하지 못한다는 것을 의미한다. 그러나, 할당된 객체의 프로퍼티 및 값은 변경할 수 있다.
1 2 3 4 5
const user = { name: 'Kim' }; user = {}; // TypeError: Assignment to constant variable.
// 객체의 내용은 변경할 수 있다. user.name = 'Ro';
var 와 let 과 const 활용
let: 재할당이 필요한 변수에 사용한다. const: 재할당이 필요없는 변수에 사용한다. var: ES6에서는 사용하지 않는다.
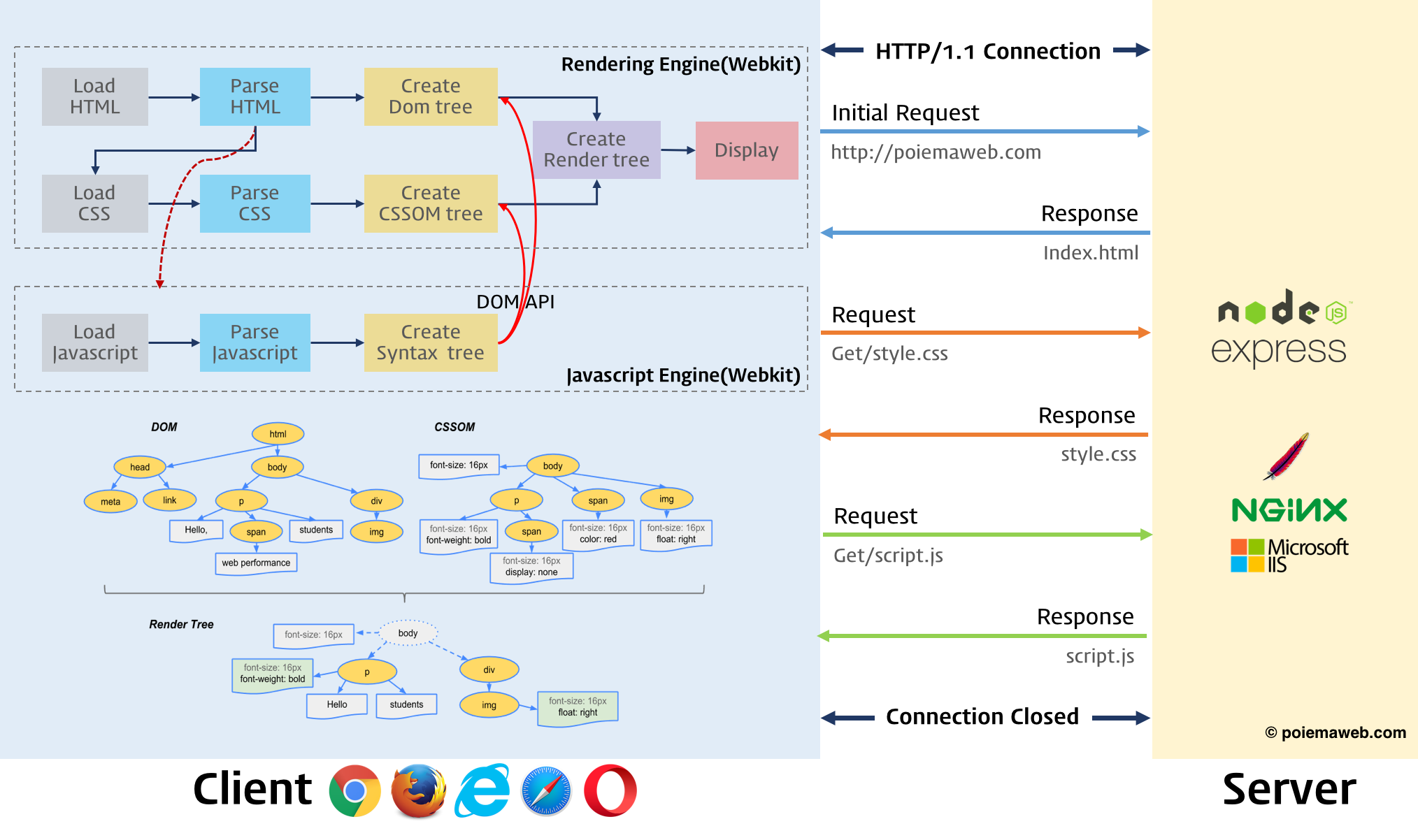
브라우저의 핵심 기능은 사용자가 브라우저에서 URL 입력창에 어떤 사이트를 입력하게 될 때, 그 사이트의 서버에 요청(Request)을 하고, 서버로부터 응답(Response)을 받아 브라우저에 그 사이트의 웹페이지를 표시하는 것이다. 이때, 브라우저는 서버로부터 HTML, CSS, Javascript, 그리고 이미지 파일 등을 받는데, 그 과정은 다음과 같다.
브라우저가 서버에 첫 요청을 하고, 서버는 먼저 index.html을 응답으로 브라우저에 보낸다.
브라우저의 렌더링 엔진에 있는 HTML 파서에 의해 파싱(해독)되어, DOM 트리를 생성한다.
HTML 파서가 html 파일을 파싱할 때, css 태그를 만나면 다시 서버에 요청하고, 서버는 css 파일을 응답으로 브라우저에 보내준다.
그러면, 브라우저의 렌더링 엔진에 있는 CSS 파서에 의해 파싱되어, CSSOM 트리를 생성한다.
또한, HTML 파서는 script 태그를 만나게 되면, 자바스크립트 코드를 실행하기 위해, DOM 생성 프로세스를 중지하고, 자바스크립트 엔진으로 제어 권한을 넘긴다.
그리고, 다시 서버에 요청해, 응답으로 자바스크립트 파일을 응답받아, 자바스크립트 엔진은 자바스크립트 파일을 파싱하여 실행한다.
자바스크립트의 실행이 완료되면, 다시 HTML 파서로 제어 권한을 넘겨서 브라우저가 중지했던 시점부터 DOM 생성을 재개한다.
DOM 생성이 완료되면, DOM과 CSSOM 트리는 최종적으로 렌더 트리로 결합하게 된다.
이 렌더 트리를 기반으로 브라우저는 웹페이지를 화면에 표시하게 된다.
이처럼, 브라우저는 동기적으로 HTML/CSS/Javascript를 처리한다. 이는 script 태그의 위치에 따라 블로킹이 발생하여, DOM 생성이 지연될 수 있다는 것을 의미한다. 즉, script 태그의 위치는 중요하다.
그래서, body 요소의 가장 아래에 자바스크립트 태그를 위치시키는 것이 좋다. 그 이유는 다음과 같다.
HTML 요소들이 자바스크립트 로딩 지연으로 인해 렌더링에 지장 받는 일이 발생하지 않기 때문에, 웹페이지 로딩 시간이 단축되기 때문이다.
DOM이 완성되지 않은 상태에서 자바스크립트가 DOM을 조작하게 된다면, 에러가 발생할 수 있기 때문이다.
정렬 알고리즘이란, 원소들을 번호순이나 사전 순서와 같이 일정한 순서대로 열거하는 알고리즘이다.
정렬 알고리즘은 명함을 어떤 순서로 정리할까?와 같은 문제이다. 1만장의 명함이 있고, 가나다 순으로 정리되어 있는데, 어느 날 새로운 명함을 받았다면, 그 명함을 가나다 순에 맞춰 끼워 넣어야 한다면 그 뒤에 명함들은 한 칸씩 뒤로 밀어야 하는 번거로움이 있다. 밀리는 명함이 1장일 수도 있고, 수천장일 수도 있다. 즉, 가나다 순으로 명함을 정리해두는 것이 머릿속에서는 편리하다고 생각되더라도 실제 관리하기에는 여간 불편한 것이 아니다.
정렬 알고리즘에서 중요한 점은 2가지다.
어떤 데이터를 사용하는가?
어떤 정렬 조건을 사용하는가?
데이터를 정렬할 때, 무조건 하나의 정렬 알고리즘을 사용하는 것은 바람직하지 않다. 데이터를 정렬할 여러 가지 조건(데이터의 개수, 사용할 수 있는 메모리의 양 등)을 분석해서 가장 합당한 정렬 알고리즘을 선택하는 지혜가 필요하다.
정렬 알고리즘 종류
퀵 정렬 알고리즘(Quick Sort)
병합 정렬 알고리즘(Merge Sort)
버블 정렬 알고리즘(Bubble Sort)
선택 정렬 알고리즘(Selection Sort)
퀵 정렬 알고리즘(Quick Sort)
퀵 정렬 알고리즘: 리스트의 한 요소를 피벗(Pivot: 기준값)으로 선정한 다음, 피벗보다 작은 요소를 하위(왼쪽) 리스트로, 피벗보다 큰 요소를 상위(오른쪽) 리스트로 이동시키는 알고리즘이다.
예를 들어, 배열 [3, 9, 4, 7, 5, 0, 1, 6, 8, 2] 있다고 해보자. 여기서 피벗을 5라고 정하고, 5보다 작은 요소를 왼쪽으로, 큰 요소를 오른쪽으로 보내는 작동 방식에 대해 알아보자.
function qSort(arr) { if (arr.length == 0) { return []; } let left = []; let right = []; const pivot = arr[0]; for (let i = 1; i < arr.length; i++) { if (arr[i] < pivot) { left.push(arr[i]); } else { right.push(arr[i]); } } return qSort(left).concat(pivot, qSort(right)); } console.log(qSort([3, 9, 4, 7, 0, 1, 5, 8, 6, 2])); // [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
// random input array for test var a = []; for (var i = 0; i < 10; ++i) { a[i] = Math.floor((Math.random()*100)+1); } console.log(a); console.log(qSort(a));
위 코드의 시간복잡도를 계산하면 T(n) = nlogn 이다. 이것을 Big-O 표기법으로 나타내면 O(nlogn)이다. partion을 나누는 수가 n번인데, 이는 partion을 계속 나누다 보면, 결국 낱개가 될 때까지 나누기 때문이다. 그런데 1번 나누면, 2번째 나눌 때는 전체에서 2개로 나눈 결과를 가지고 또 나누는 것이기 때문에, 검색해야하는 데이터의 양이 줄어들었다. 마치, 이진 탐색 알고리즘과 같다. 그래서 logn번 검색하게 된다. 즉, n * logn = nlogn인 시간복잡도가 된다.
그러나, 예외도 있다. partion을 나누기 위한 pivot(기준값)이 전체 배열에서 최소값/최대값일 경우, 시간복잡도는 O(n^2)이 된다. 예를 들어, pivot(기준값)이 전체 배열에서 최소값일 경우, 제일 왼쪽으로 들어가고, 나머지 데이터에서 pivot(기준값)이 또 최소값이어서 이런식으로 된다면, 결국 모든 데이터를 모두 돌게 되어, 시간복잡도가 O(n^2)dl 된다. 하지만, 확률적으로 이런 경우는 거의 없기 때문에, 보통의 시간복잡도는 O(n^2)이 된다.
병합 정렬 알고리즘(Merge Sort)
병합 정렬 알고리즘: 함수가 호출 될때마다, 절반씩 잘라서 재귀적으로 함수를 호출하고 맨끝에 제일 작은 조각부터 두 개씩 병합해서 정렬된 배열을 병합해나가는 방식이 병합 정렬 알고리즘이다. 이미 정렬되어 있는 데이터들을 하나로 합해서 정렬하는 방법. 이러한 정렬 방법은 데이터들을 정렬하는 경우에도 사용되지만 파일에 정렬되어 있는 데이터들을 하나로 합쳐서 정렬하는 경우에도 종종 사용된다. 이미 정렬되어 있는 데이터 그룹들 혹은 묶음들을 하나로 합할 때 사용할 수 있다.
병합 정렬 알고리즘을 사용하는 경우 배열 하나에 저장된, 정렬되지 않은 데이터들을 어떤 방식으로 정렬하는 지 알아보자.
예) 정렬되지 않은 데이터가 있다고 해보자. 하나의 데이터 배열을 여러 개로 나누어서, 나중에 병합 하기 위해 묶는데, 이 묶은 데이터 그룹을 런(Run)이라고 한다. 2-way 방식은 2개씩 그룹으로 묶는다. 일단 2개씩 묶으면, 각 그룹별로 정렬을 한다. 예를 들어, 6과 1이 하나의 그룹으로 묶였다면, 1이 왼쪽에 오고, 6이 오른쪽에 오는 식으로 정렬을 한다. 그 다음으로는 2개의 런을 묶어서 하나의 런으로 합하도록 정렬한다. 만약 2, 3 런과 5, 7 런이 하나의 런으로 합쳐진 다음, 2, 3, 5, 7 사이에서 정렬이 된다. 이렇게 런(그룹)을 계속 합쳐나가면서 하나의 런으로 모두 합쳐 정렬하는 방식을 병합 정렬 알고리즘이라고 한다.
병합 정렬의 핵심은 1부터 하나의 런에 들어가는 데이터의 수를 2의 배수 기준으로 늘려서 병합하는 과정을 반복하는 것이다. 이와 같이 반복해서 병합하게 되면 결국 전체 데이터를 모두 정렬하게 되는 결과를 얻을 수 있다.
병합 정렬 알고리즘의 성능은 수치적으로만 보면 퀵 정렬 알고리즘과 비슷하다. 퀵 정렬 알고리즘이나 병합 정렬 알고리즘이나 데이터를 나눈 후에 재귀 호출을 사용하기 때문이다.
위 코드의 시간복잡도를 계산하면 T(n) = nlogn 이다. 이것을 Big-O 표기법으로 나타내면 O(nlogn)이다. n개 만큼씩 logn번 돌기 때문에, 병합 정렬 알고리즘의 시간복잡도는 O(nlogn)이 된다. partition이 낱개가 될 때까지 쪼개지니까 n번 호출에, 1번 호출당 검색해야하는 데이터의 양이 절반씩 줄어드니까 logn이다. 따라서 n * logn = nlogn 시간복잡도가 된다. nlogn 시간복잡도는 이진 탐색 알고리즘에서 한 번 돌 때마다 검색 영역에 절반씩 떨어지는 것과 같은 원리이다.
병합 정렬 알고리즘은 물리적으로 배열의 가운데 값으로 partition을 나누기 때문에 최악의 경우에도 시간복잡도는 O(nlogn)이다. 퀵 정렬 알고리즘으로 따지면, pivot(기준값)을 잘 골랐을 때랑 비슷하다. 퀵 정렬 알고리즘도 최악의 경우가 아니라면, 병합 정렬 알고리즘과 같은 시간복잡도는 O(nlogn)이다.
하지만, 병합 정렬 알고리즘은 실행시에 별도의 저장공간을 필요로 하기 때문에, 공간을 사용할 수 없는 경우에는 퀵 정렬 알고리즘을 사용해야 한다.
버블 정렬 알고리즘(Bubble Sort)
버블 정렬 알고리즘: 순차적으로 바로 옆에 있는 데이터와 비교해서 옆의 데이터가 크면 자신과 위치를 바꾼다. 즉, 첫 번째 데이터가 가장 크다면 계속 옆에 있는 데이터와 자리를 바꾸면서 해당 데이터는 결국 맨 끝으로 이동하게 된다. 그리고 두 번째 위치에 있는 데이터를 또다시 옆에 있는 데이터와 비교한다. 이와 같은 과정을 마지막 데이터의 바로 전 데이터까지 반복해서 실행한다. 이 형태가 마치 버블이 부글부글 올라가는 것과 같다고 하여 버블 정렬 알고리즘이라고 한다.
예를 들어, [3, 5, 4, 2, 1] 배열이 있으면, 먼저 3과 5를 비교해서 3이 5보다 크면 둘을 바꾼다. 그런데 여기서는 5가 크므로 그대로 둔다. 그 다음은 5와 4를 비교한다. 이때, 5가 4보다 크므로 그 둘을 바꾼다. 그럼 [3, 4, 5, 2, 1] 배열이 이렇게 바뀐다. 이런식으로 비교하면 결국 5가 제일 마지막으로 이동하게 된다. 즉, [3, 4, 2, 1, 5] 배열이 된다. 그럼 가장 큰 수인 5가 배열에 제일 오른쪽으로 이동하게 되고, 다시 맨 처음부터 이웃 숫자끼리 비교한다. 이런식으로 가장 큰 수를 오른쪽으로 이동시켜 정렬하는 방식을 버블 정렬 알고리즘이라고 한다.
성능이 좋은 편이 아니라, 자주 사용되지는 않는다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// 스왑 헬퍼 => 배열의 위치를 바꾼다. function swap(arr, index1, index2) { let temp = arr[index1]; arr[index1] = arr[index2]; arr[index2] = temp; }
// 버블 정렬은 서로 이웃한 데이터들을 비교하며 가장 큰 데이터를 가장 뒤로 보내며 정렬하는 방식 function BubbleSort(arr) { let len = arr.length; for(let outer = len; outer > 1; outer--) { for(let inner = 0; inner < outer; inner++) { if( arr[inner] > arr[inner + 1]) { swap(arr, inner, inner+1); } } } return arr; };
위 코드의 시간복잡도를 계산하면 T(n) = n^2 이다. 이것을 Big-O 표기법으로 나타내면 O(n^2)이다. 앞에서부터 한 개씩 뒤로 가면서 전체 배열 데이터를 돌기 때문에 n^2 만큼 시간이 걸린다.
선택 정렬 알고리즘(Selection Sort)
선택 정렬 알고리즘: 데이터의 처음부터 끝까지 쭉 훑어가면서 가장 작은 값을 찾아 그 값을 첫 번째 데이터와 자리를 바꾸고, 두 번째로 작은 데이터를 찾아 두 번째의 데이터와 자리를 바꾸는 방법으로 구현하는 정렬 알고리즘이다.
예를 들어, [3, 5, 4, 2, 1] 배열이 있으면, 변수 min = 3으로 할당하고, 그 다음 데이터인 5부터 하나씩 비교해 나간다. 이때, 가장 작은 값이 1 이므로 맨 앞에 있는 3과 1을 바꾼다. 그리고, 다시 두번째 요소인 5부터 오른쪽으로 하나씩 비교하면서 가장 작은 값을 찾아 5와 바꾼다. 이런식으로 정렬하는 방식이 선택 정렬 알고리즘이다.
// 스왑 헬퍼 => 배열의 위치를 바꾼다. function swap(arr, index1, index2) { let temp = arr[index1]; arr[index1] = arr[index2]; arr[index2] = temp; }
// 선택 정렬은 정렬되지 않은 데이터들에 대해 가장 작은 데이터를 찾아 가장 앞의 데이터와 교환해나가는 방식 function SelectionSort(arr) { let min; for(let outer = 0; outer < arr.length -1; ++outer) { min = outer; for(let inner = outer + 1; inner < arr.length; ++inner) { if( arr[inner] < arr[min] ) { min = inner; } } swap(arr, outer, min); } return arr; }
위 코드의 시간복잡도를 계산하면 T(n) = n^2 이다. 이것을 Big-O 표기법으로 나타내면 O(n^2)이다. 앞에서도 한칸씩 가면서 갈때마다 각 배열 요소를 한번씩 다시 돌기 때문에, n^2 만큼 시간이 걸린다.
Fibonacci 수열이란, 다음 수는 앞의 두 수의 합으로 이루어진 수열을 말한다. 규칙에 따라 수를 나열해 보면, 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144…와 같은 수열이 된다.
[Problem]
피보나치 수는 F(0) = 0, F(1) = 1일 때, 2 이상의 n에 대하여 F(n) = F(n-1) + F(n-2) 가 적용되는 점화식입니다. 2 이상의 n이 입력되었을 때, fibonacci 함수를 제작하여 n번째 피보나치 수를 반환해 주세요. 예를 들어 n = 3이라면 2를 반환해주면 됩니다. 즉, 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144…에서 3번째 피보나치의 수는 2이다.
[Algorithms]
n이 0일 경우, 0을 리턴하고, 1일 경우, 1을 리턴한다.(피보나치 수열에서 0번째는 0, 1번째는 1이기 때문이다.)
n이 2이상일 경우, 앞의 두 수의 합으로 계산되는 재귀 호출을 사용하여 구현한다.
함수에서 n이라는 정수를 받을 것이고, n은 몇 번째 피보나치 수를 구할 것인지를 의미한다. 예를 들어, n이 3이면, 피보나치 수열 중 3번째 피보나치 수를 구하는 함수를 구현하는 것이고, 그 값은 2이다.
[Solution]
1 2 3 4 5 6 7 8 9 10 11 12
function fibonacci(num){ var a = 1, b = 0, temp;
while (num >= 0){ temp = a; a = a + b; b = temp; num--; }