알고리즘이란, 어떤 목적이나 결과물(프로그램)을 만들어내기 위해 거쳐야 하는 일련의 과정들을 말한다. 어떤 프로그램을 만드는 데 있어서 방법은 여러가지가 있을 수 있다. 예를 들어, 어떤 케익 1개를 100가지 방법으로 자를 수 있는 것처럼, 하나의 문제를 여러가지의 알고리즘으로 풀 수 있다. 그렇기 때문에, 여러 알고리즘 중 최선의 알고리즘으로 하는 것이 좋다.
어떤 프로그램 개발을 위해 코딩을 할 때, 여러가지의 알고리즘으로 풀 수 있지만, 최선의 알고리즘으로 푸는 것이 (웹페이지 등의) 성능을 위해서 좋다. 이때, 이 성능 분석을 위해 필요한 것이 복잡도이다.
복잡도
복잡도에는 크게 2가지가 있다.
시간 복잡도: 알고리즘이 문제를 해결하기 위한 연산의 횟수(얼마나 많은 연산이 수행되는지)
공간 복잡도: 메모리 사용량(얼마나 많은 양의 메모리를 차지하는지)
이런 복잡도를 가지고 작성한 코드 알고리즘의 성능을 분석해서, 어떻게 하면 더 적은 연산으로(시간 복잡도), 더 적은 메모리를 차지하여(공간 복잡도) (웹페이지 등의) 성능을 좋게 할 수 있다.
알고리즘의 성능을 평가하기 위해서는 작성된 코드의 시간복잡도 및 공간복잡도를 계산하고, 이를 점근적 표기법으로 나타내어 평가한다. 이때 점근적 표기법이란, 각 알고리즘이 주어진 데이터의 크기를 기준으로 코드에서의 연산의 횟수 또는 메모리 사용량이 얼마나 되는지를 비교할 수 있는 방법이다. 이 방법에는 Big-O, 오메가, 세타 등이 있다.
이 방법중에서 Big-O 표기법에 대해 알아보자.
Big-O 표기법
Big-O 표기법이란, 계산된 복잡도를 O(n) 이런식으로 표기하는 방식인데, 이때, n은 최고차항의 차수가 된다. 예를 들어, T(n) = n^2+ 2n + 1 으로 시간복잡도가 계산되었다면, O(n^2)으로 표기하는 것이 Big-O 표기법이다.
대표적인 복잡도를 Big-O 표기법으로 작성한 것은 다음과 같다.
O(1): 상수 시간
입력값 n이 주어졌을 때, 알고리즘이 문제를 해결하는 데 오직 한 단계만 거친다.
O(logn): 로그 시간
입력값 n이 주어졌을 때, 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어든다.
function addTwoNumbers(num1, num2) { return num1 + num2; // 1번 실행 }
console.log(addTwoNumbers(1, 3)); // 4
시간복잡도를 T(n)이라고 하는데, 위 코드의 시간복잡도를 계산하면 T(n) = 1 이다. 이것을 Big-O 표기법으로 나타내면 O(1)이다. 1인 이유는 Big-O 표기법에서 O(n)의 n은 최고차항의 차수를 나타내는데, 위의 경우 n^0이므로, 1이된다.
2. 정렬되어 있는 배열에서 최소값과 최대값을 구하는 경우
1 2 3 4 5 6 7 8
const numbers = [1, 2, 3, 4, 5, 10]; // 배열의 요소들이 순서대로 정렬되어 있다. function FindLargestNumber(items) { let smallest = items[0]; // 1번 실행 let largest = items[items.length - 1]; // 1번 실행 return (largest - smallest); // 1번 실행 }
console.log(FindLargestNumber(numbers)); // 9
위 코드의 시간복잡도를 계산하면 T(n) = 3 이다. 이것을 Big-O 표기법으로 나타내면 O(1)이다.
3. 값을 검색할 때, 객체에서 키를 알거나, 배열에서 인덱스를 알고 있으면 언제나 한 단계만 걸린다.
1 2 3 4 5 6 7 8 9 10 11
function isCryptoCurrency(name) { return cryptoCurrency[name]; // 1번 실행 }
위 코드의 시간복잡도를 계산하면 T(n) = 1 + n/2 이다. 이것을 Big-O 표기법으로 나타내면 O(logn)이다.
O(n): 직선적 시간(linear time)
문제를 해결하기 위한 단계의 수와 입력값 n이 1:1 관계를 가진다.
for문을 1번 사용하는 경우
예를 들어, 배열이 정렬되어 있지 않을 경우, 최소 및 최대값을 찾기 위해 배열의 모든 숫자를 탐색하여, 비교를 수행한다. 이 경우, 수행시간은 배열의 크기에 따라 늘어난다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
const numbers = [1, 9, 3, 10, 16]; function FindLargestGap(items) { let smallest = items[0]; // 1번 실행 let largest = items[0]; // 1번 실행 for (let i = 1; i < items.length; i++) { if (items[i] < smallest) { smallest = items[i]; } else if (items[i] > largest) { largest = items[i]; } } // n번 실행 return (largest - smallest); // 1번 실행 }
console.log(FindLargestGap(numbers));
위 코드의 시간복잡도를 계산하면 T(n) = 3 + n 이다. 이것을 Big-O 표기법으로 나타내면 O(n)이다.
O(n^2): 2차 시간(quadratic time)
문제를 해결하기 위한 단계의 수는 입력값 n의 제곱이다.
중첩 for 문을 사용할 경우, 첫번째 for 문의 각 요소(n) x 두번째(안에있는) for 문의 각 요소(n) = n x n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
const number = [2, 10, 1, 4, 3, 10, 5]; function FindLargestGap(items) { let gap; // 1번 실행 let maxGap = 0; // 1번 실행 for (let i = 0; i < items.length; i++) { for(let j = 0; j < items.length; j++) { gap = items[i] - items[j]; if (gap < 0) { gap = gap * -1; } if (gap > maxGap) { maxGap = gap; } } } // n^2번 실행 return maxGap; // 1번 실행 }
console.log(FindLargestGap(numbers)); // 9
위 코드의 시간복잡도를 계산하면 T(n) = 3 + n^2 이다. 이것을 Big-O 표기법으로 나타내면 O(n^2)이다.
Hoisting(호이스팅)이란, Javascript의 모든 선언문(var, let, const, function, function*, class)이 해당 Scope의 최상단으로 옮겨진 것처럼 행동하는 것을 말한다. C 언어 등 C-family 언어와는 다르게, Javascript의 모든 선언문은 ‘호이스팅’이 되는 Javascript만의 특징이 있다.
Hoisting에는 크게 2가지가 있다.
변수 호이스팅
함수 호이스팅
변수 호이스팅(Variable Hoisting)
변수 호이스팅이란, Javascript의 변수 선언문(var, let, const)이 해당 Scope의 최상단으로 옮겨진 것처럼 행동하는 것을 말한다. 즉, Javascript의 모든 선언문이 선언되기 전부터, 변수를 참조할 수 있게 된다.
1 2 3 4 5 6 7
console.log(num); // 1. -> undefined var num = 100; console.log(num); // 2. -> 100 { var num = 5; } console.log(num); // 3. -> 5
위 코드를 처음 봤을 때, 첫줄의 출력 값은 Error가 날 것이라고 예상 할 수 있다. 그러나, 위 Javascript의 코드는 변수 호이스팅이 있기 때문에, undefined를 출력한다.
Javascript 엔진이 위 코드를 읽어들일 때, 제일 먼저 선언문부터 읽는다. 그리고, 그 중 제일 첫번째로 선언된 변수를 찾아, 그 변수를 선언하고, 초기화를 한다. 이때, 변수의 호이스팅 때문에, 선언문은 해당 Scope의 최상단, 즉 제일 윗줄로 옮겨진 것처럼 행동하여, ‘num’을 출력(console.log(num)) 하기 전에, 변수가 존재하는 것처럼 행동하고, 이 변수는 선언이 되고, 초기화까지 되었기 때문에(변수를 초기화하면, ‘undefined’를 메모리에 할당한다.), console.log(num)의 결과로는 ‘undefined’가 출력된다.
기본적으로, var 키워드로 선언된 변수는 선언 단계와 초기화 단계가 한번에 이루어진다. 변수가 선언이 될 때, 스코프에 Variable Object가 생성이 되고, 여기에 변수가 등록이 되어있어, 변수 선언문 이전에 변수에 접근해도 에러가 발생하지 않는다. 다만, 초기화 단계에서 변수는 메모리에 공간을 확보한 후, undefined를 저장하기 때문에, undefined를 반환한다. 이후, 변수 할당문(var num = 100;)에 도달하여 값의 할당이 이루어진다.
호이스팅 관점에서 다시 코드를 보자.
1 2 3 4 5 6 7
console.log(num); // 1. -> undefined var num = 100; console.log(num); // 2. -> 100 { var num = 5; } console.log(num); // 3. -> 5
‘1.’이 실행되기 이전에 var num = 100;이 호이스팅되어 ‘1.’ 구문 위에(최상단) var num;가 옮겨진 것처럼 된다. 실제로 변수 선언이 코드 레벨로 옮겨 진것은 아니고, 변수 객체(Variable Object)에 등록되고, undefined로 초기화된 것이다. 그러나, 변수 선언 단계와 초기화 단계가 할당 단계와 분리되어 진행되기 때문에, 이 단계에서는 num에 undefined가 할당되어 있다. 변수 num에 값이 할당되는 것은 두번째 행(var num = 100;)에서 실시된다.
마지막 줄에서는 숫자 5가 출력이 되는데, 이는 코드 블록안에서 새롭게 변수가 중복 선언이 되어 num의 값이 5로 바뀌었기 때문이다. Javascript는 function-level scope를 갖기 때문에, 변수의 유효범위가 코드 블록에는 영향이 없다.
함수 호이스팅(Function Hoisting)
함수 호이스팅이란, Javascript의 함수 선언문(function)이 해당 Scope의 최상단으로 옮겨진 것처럼 행동하는 것을 말한다. 즉, Javascript의 모든 선언문이 선언되기 전부터, 함수를 호출할 수 있게 된다. 함수선언의 위치와는 상관없이 코드 내 어느 곳에서든지 호출이 가능하게 만드는 것을 말한다. 단, 함수선언식에만 적용이 된다.
함수선언식으로 정의된 함수는 자바스크립트 엔진이 스크립트가 로딩되는 시점에 바로 초기화하고 이를 VO(variable object)에 저장한다. 즉, 함수 선언, 초기화, 할당이 한번에 이루어진다. 그렇기 때문에 함수 선언의 위치와는 상관없이 소스 내 어느 곳에서든지 호출이 가능하다.
1 2 3 4 5
square(5); // 25
function square(number) { return number * number; }
다음은 함수표현식으로 함수를 정의한 경우이다.
1 2 3 4 5
var res = square(5); // TypeError: square is not a function
var square = function(number) { return number * number; }
위와 같이 에러가 발생한 이유는, 함수표현식의 경우는 함수 호이스팅이 아니라, 변수 호이스팅이 발생하기 때문이다.
함수표현식은 함수선언식과는 달리 스크립트 로딩 시점에 변수 객체(VO)에 함수를 할당하지 않고, runtime에 해석되고 실행된다. 즉, 선언과 초기화까지만 하여, undefined를 호출하는 것과 같기 때문에, 에러가 난다.
그래서, 더글러스 크락포드는 ‘함수표현식’만 사용할 것을 권한다. 왜냐하면, 에러가 나서 미리 호출을 방지하기 때문이다. 왠만하면, 선언문 이전에 호출하지 않는 것이 좋다.
변수와 함수의 호이스팅의 차이점:
함수 호이스팅: 함수선언문 이전에 함수가 호출이 된다.(함수 선언식으로 함수를 선언했을 경우)
변수 호이스팅: 함수표현식으로 함수를 선언했을 경우, 함수표현식 이전에 함수를 호출하면, 에러가 난다.
왜냐하면, 함수표현식은 변수 호이스팅을 따르기 때문에, 할당은 안되고, 초기화까지만 되기 때문이다. 즉, 초기화까지만 되면 undefined를 호출하는 것과 같기 때문이다. undefiend() 이런형식으로 나온다는 의미이기 때문에, 에러가 난다.
DOM이란, 브라우저가 서버에게 요청하여, 응답으로 받은 웹 문서(HTML, XML, SVG 등)를 브라우저의 렌더링 엔진이 로드하고, 파싱하여 브라우저가 이해할 수 있는 형태로 구성된 것을 말한다. 이 DOM은 자바스크립트를 이용해 동적으로 변경이 가능하고, 이 변경된 DOM은 렌더링에 반영된다. 이때, 자바스크립트로 이 DOM에 접근하고 수정할 수 있는 DOM API가 있으며, 이 DOM API가 가지고 있는 프로퍼티와 메소드로 정적인 웹페이지에 접근하여 동적으로 변경할 수 있다.
DOM은 W3C의 공식 표준이고, HTML, JavaScript에서 정의한 표준이 아니다.
DOM의 기능
HTML 문서에 대한 모델 구성
브라우저가 이해할 수 있는 형태로 HTML 문서를 모델로 구성하여 메모리에 생성하는데, 이때 모델은 객체의 트리로 구성된다.
HTML 문서 내의 각 요소에 접근 및 수정
객체의 트리로 구성되어있는 모델 내의 각 객체에 접근 및 수정할 수 있는 프로퍼티와 메소드를 제공한다. 이때, DOM이 수정되면, 브라우저를 통해 사용자가 보게 될 내용 또한 변경된다.
DOM 구조
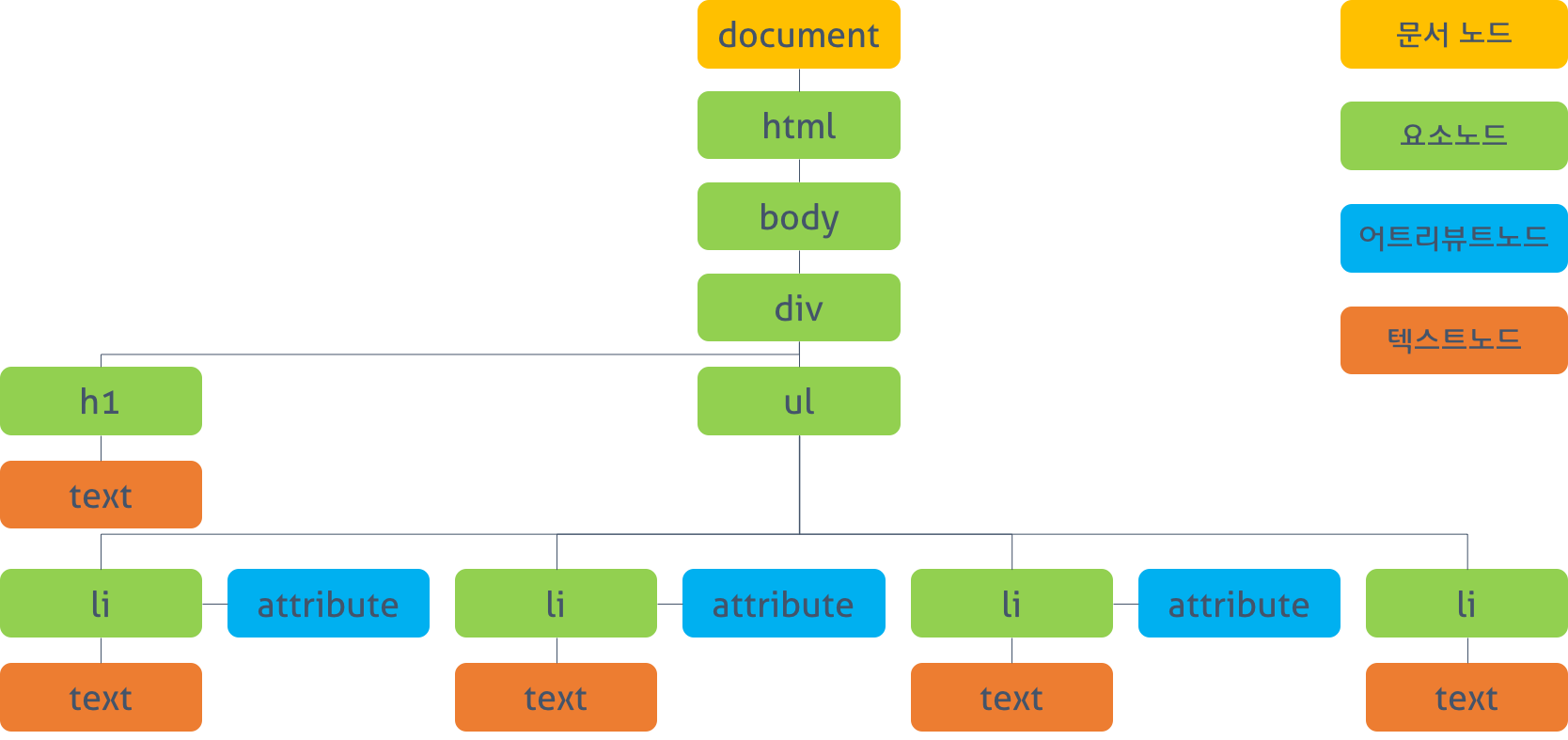
DOM 구조는 브라우저가 이해할 수 있는 형태로 HTML 문서를 모델로 구성하여 메모리에 생성하는데, 이때 모델은 객체의 트리로 구성되었다고 하여, DOM tree라고 부른다. DOM tree는 HTML 문서의 모든 요소와 요소의 attribute, text 등을 각각의 객체로 만들고, 이들 객체간에 관계를 부자 관계로 표현하는 tree(나무 가지)처럼 구성되어있다.
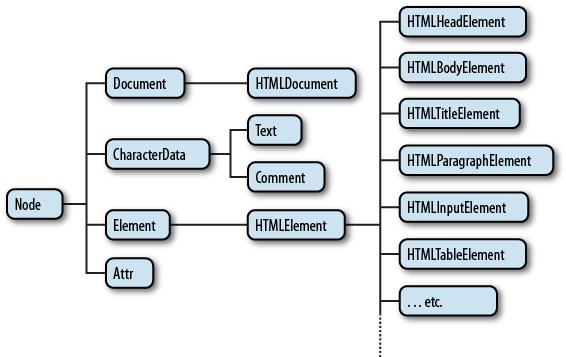
Element Node란, html, body, div 등 HTML 요소를 말한다. Element Node는 서로 부자 관계를 가지며, 이 부자 관계를 통해 정보를 구조화한다. Attribute Node 또는 Text Node에 접근하기 위해서는 먼저 Element Node에 접근해야 한다. 모든 Element Node는 요소별 특성을 표현하기 위해 HTMLElement 객체를 상속한 객체로 구성된다.
Write a function that takes an integer and returns an array [A, B, C], where A is the number of multiples of 3 (but not 5) below the given integer, B is the number of multiples of 5 (but not 3) below the given integer and C is the number of multiples of 3 and 5 below the given integer.
For example, solution(20) should return [5, 2, 1]
1 2 3
function solution(number){
}
[Algorithms]
Declare variables for the number of multiples below the given integer(3, 5, 15)
Add counts for the number of multiples below the given integer using ‘for’ statement
get an array of the variables
[Solution]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
function solution(number){ var num3 = 0; var num5 = 0; var num15 = 0; for(var i = 1; i < number; i++) { if((i % 3 === 0) && (i % 5 !== 0)) { num3 += 1; } else if((i % 5 === 0) && (i % 3 !== 0)) { num5 += 1; } else if(i % 15 === 0) { num15 += 1; } } var result = [num3, num5, num15]; return result; }
var parent = document.querySelector('.parent'); parent.addEventListener('click', getEventTarget);
만약 첫번째 버튼(button 1)을 클릭하게 되면 결과는 위와 같이 나온다. e.target은 실제로 이벤트를 발생시킨 요소로, 첫번째 버튼(button 1)이 된다. 그러나, e.currentTarget은 이벤트에 바인딩된 DOM 요소(addEventListener 메소드 앞에 기술된 객체)로, 이벤트가 발생된 곳은 첫번째 버튼이지만, 이벤트에 바인딩된 DOM 요소는 parent(부모요소)이기 때문에, e.currentTarget은 parent 요소가 된다. 또한, addEventListener 함수에서 지정한 이벤트 핸들러 내부의 this는 Event Listener에 바인딩된 요소(parent)를 가리킨다. 이것은 이벤트 객체의 currentTarget 프로퍼티와 같다.
Event.type && Event.keyCode
Event.type: 발생한 이벤트의 종류
Event.keyCode: 발생한 이벤트의 키보드 번호
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// HTML <div class="parent"> <input type="text" class="val"> <button id="btn">button</button> </div>
var inputBox = document.querySelector('.val'); inputBox.addEventListener('keyup', getEventType);
어떤 알파벳 하나를 입력하고, 키보드에서 ‘enter’를 입력하게 되면 e.type은 ‘keyup’이 되고, e.keyCode는 13이 된다. 즉, 발생한 이벤트의 타입은 ‘keyup’이고, 발생한 이벤트의 키보드 번호(enter의 키보드 번호)는 13이다.
Event.preventDefault() && Event.stopPropagation()
Event.preventDefault(): 이벤트의 기본 동작을 중단
Event.stopPropagation(): 이벤트의 전파(버블링/캡처링)를 중단
Event.preventDefault()
1 2 3 4 5 6 7 8 9 10 11 12 13
// HTML <a href="https://cheonmro.github.io/">블로그로 이동</a>
// Javascript var elem = document.querySelector('a');
elem.addEventListener('click', function (e) { console.log(e.cancelable); // true
// 이벤트의 기본 동작을 중단 e.preventDefault(); });
원래는 ‘a’태그를 클릭하면 블로그로 이동을 해야하지만, 위와 같이 e.preventDefault()를 사용하게 되면, 이벤트의 기본 동작을 중단할 수 있다. 단, Event.cancelable가 true일 경우만 가능하다. Event.cancelable는 이벤트 객체의 프로퍼티로, 요소의 기본 동작을 중단할 수 있는지에 대한 여부(true/false)를 나타낸다.
Event.stopPropagation()
어느 한 요소를 이용하여 이벤트를 처리한 후, 이벤트가 부모 요소로 이벤트가 전파되는 것을 중단하기 위해 사용되는 메소드이다.
function clickDiv(event) { console.log('Event for div'); } function clickPara(event) { console.log('Event for p'); } function clickLink(event) { event.stopPropagation(); // 이벤트의 전파를 중단함. console.log('Stop Propagation!') }
위 코드에서 paraBox 요소를 클릭하게 되면, 부모요소로 이벤트가 전파된다. 그러나, linkBox 요소를 클릭하게 되면, 이벤트는 부모요소로 전파되지 않는다.
var con1 = document.querySelector('#content1').addEventListener('click', getColor); var con2 = document.querySelector('#content2').addEventListener('click', getColor); var con3 = document.querySelector('#content3').addEventListener('click', getColor);
만약 이벤트 위임을 안한다면, 위 코드처럼 모든 자식 요소에 이벤트 핸들러를 바인딩해줘야 한다. 위 코드처럼 3개는 크게 문제가 안될 수도 있지만, 만약 10개, 100개면 어떨까? 그렇게 되면 자식요소가 너무 많아지기 때문에, 각 자식요소에 이벤트 핸들러를 바인딩하는 것도 힘들고, 코드 가독성도 안좋게 되고, 결국 실행속도도 저하가 된다.
var allContents = document.querySelector('#parent').addEventListener('click', getColor);
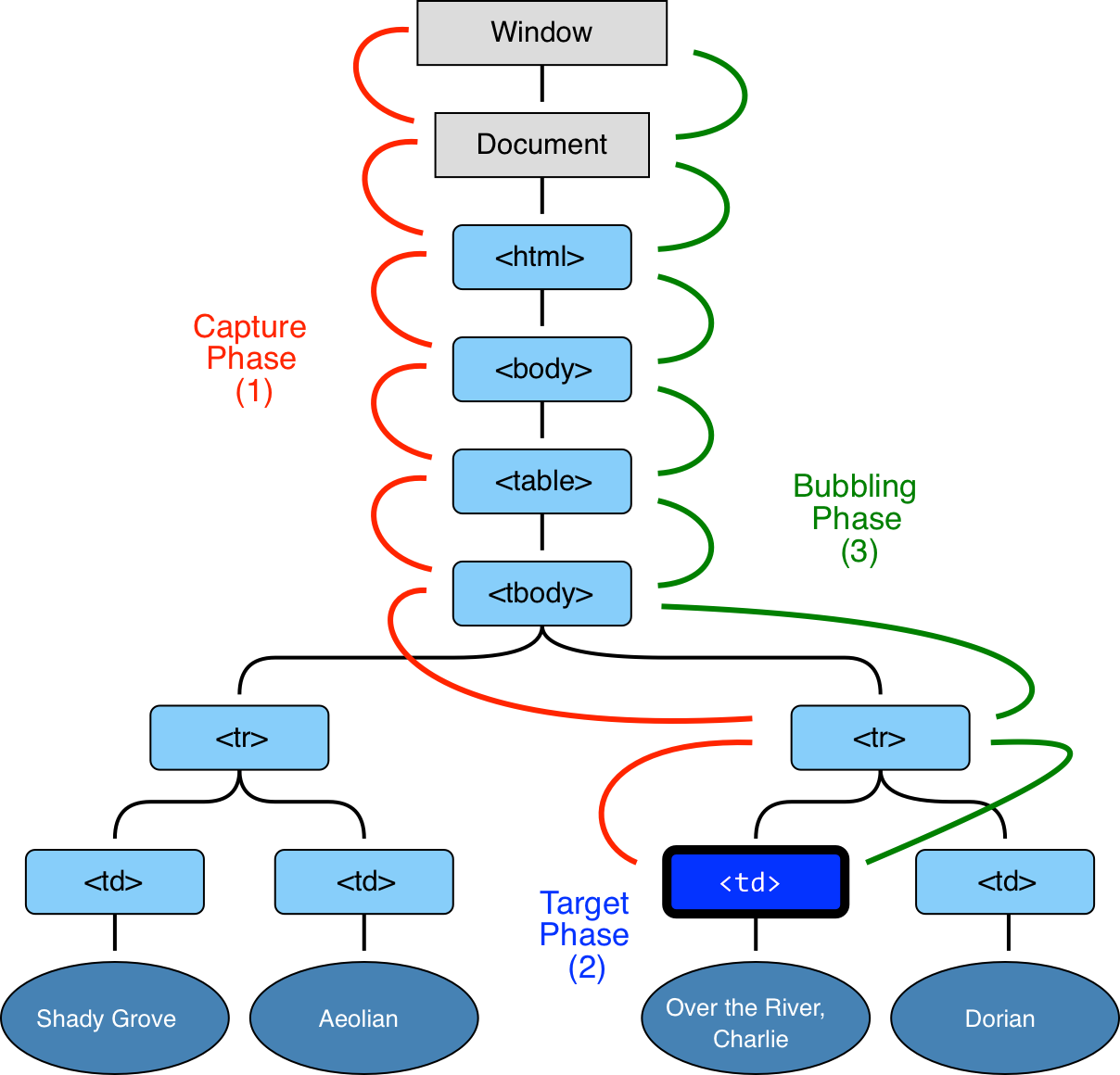
위와 같이 부모요소 1개에만 이벤트 핸들러를 바인딩하게 되면, 어떤 자식(하위)요소에서 이벤트가 발생하게 되면 그 이벤트를 부모요소가 감지하여 addEventListener의 콜백함수가 실행되게 된다. 이렇게 하위요소에서 이벤트가 발생하여 상위요소로 전달되어 상위요소가 그 이벤트를 감지하는 것을 버블링이라고 한다. 그 반대 방향으로 감지하는 것을 캡처링이라고 한다. 이부분을 잘 이해해야 이벤트 위임을 잘 할 수 있다.
// Javascript var divAncestor = document.querySelector('#ancestor'); var ulParent = document.querySelector('#parent'); var liChild = document.querySelector('#child');
divAncestor.addEventListener('click', function() { console.log('Event for div'); })
ulParent.addEventListener('click', function() { console.log('Event for ul'); })
liChild.addEventListener('click', function() { console.log('Event for li'); })
위 코드에서 ‘child’(li 요소)를 클릭하면, 아래와 같은 결과가 나온다.
1 2 3
Event for li Event for ul Event for div
자식요소인 li를 클릭하면, li에서 이벤트가 발생하고, 그 부모요소인 ul에서 이벤트가 발생하고, ul의 부모요소인 div에서 이벤트가 발생한다. 즉, 이벤트가 발생한 곳부터 위로 하나씩 이벤트가 발생하게 된다. 이때, 어떤 요소에 이벤트가 없을 경우(addEventListener가 없을 경우), 그 요소에서는 이벤트가 발생하지 않는다.
// Javascript function getColor(e) { e.target.style.color = 'red'; }
var parent = document.querySelector('.parent'); parent.addEventListener('click', getColor);
위 코드에서는, 모든 자식요소에 이벤트 핸들러를 바인딩하는 대신에, 부모요소 1개에만 이벤트핸들러를 바인딩했는데, 이것을 이벤트 위임이라고 한다. 따라서, 자식요소가 button1, button2 둘 중 어느 곳을 클릭을 하더라도, 이벤트가 부모요소로 전달되어, 부모요소인 parent 요소에서 이벤트를 감지하고 이벤트를 발생시킨다.
Event Capturing(이벤트 캡처링)
이벤트 캡처링이란, 자식 요소에서 발생한 이벤트가 부모 요소부터 시작하여 이벤트를 발생시킨 자식 요소까지 도달하는 것을 말한다.
// Javascript var divAncestor = document.querySelector('#ancestor'); var ulParent = document.querySelector('#parent'); var liChild = document.querySelector('#child');
divAncestor.addEventListener('click', function() { console.log('Event for div'); }, true)
ulParent.addEventListener('click', function() { console.log('Event for ul'); }, true)
liChild.addEventListener('click', function() { console.log('Event for li'); }, true)
참고로, 캡처링을 적용하려면, addEventListener 메소드의 세번째 매개변수에 true를 설정해야 한다. 설정하지 않으면 default로 버블링이다.
위 코드에서 ‘child’(li 요소)를 클릭하면, 아래와 같은 결과가 나온다.
1 2 3
Event for div Event for ul Event for li
자식요소인 li를 클릭하면, 최상위 부모요소인 div에서 먼저 이벤트가 발생하고, 아래 방향으로 하나씩 이벤트가 발생한다. 즉, 버블링과 반대로, 이벤트가 발생한 곳은 자식요소이나, 이벤트를 감지하는 곳은 최상위 부모요소부터 시작하여 실제로 이벤트가 발생한 요소까지 도달하는데, 이런식으로 이벤트를 감지하는 것을 이벤트 캡처링이라고 한다.
// Javascript var divAncestor = document.querySelector('#ancestor'); var liChild = document.querySelector('#child');
divAncestor.addEventListener('click', function() { console.log('Event for div'); })
liChild.addEventListener('click', function() { console.log('Event for li'); })
위 코드에서 ‘child’(li 요소)를 클릭하면, 아래와 같은 결과가 나온다.
1 2
Event for div Event for li
즉, ul요소는 이벤트가 없기 때문에(addEventListener가 없다.), 이벤트가 발생하지 않고, 그 부모요소인 div요소부터 이벤트가 발생하고, 그 다음 li요소에서 이벤트가 발생하게 된다.
또한, li요소가 아닌, ul을 클릭하게 되면, 최상위 요소인 div요소에서 이벤트가 발생하여, 이벤트가 발생한 ul요소까지 이벤트가 도달하게 된다. 즉, 이벤트가 어디서 발생하는 것과는 상관없이, 최상위 부모요소에서부터 이벤트가 발생하기 시작하여, 실제로 이벤트가 발생한 곳까지 가는 방식을 이벤트 캡처링이라고 한다.